Swetha DhanasekarinNerd For TechIntroduction to Exploratory Data Analysis (EDA)Exploratory Data Analysis (EDA) is the process of visualizing and analyzing data to extract insights from it. Sometimes what we see with…5 min read·Mar 19, 2021--1--1
Swetha DhanasekarParquet file -ExplainedI realize that you may have never heard of the Apache Parquet file format. Similar to a CSV file, Parquet is a type of file.3 min read·Mar 16, 2021----
Swetha DhanasekarinDataDrivenInvestorCross-Validation TechniquesFor any model in machine learning it is considered as best practice if the model is tested with an independent data set. Usually, any…4 min read·Mar 15, 2021----
Swetha DhanasekarinDataDrivenInvestorA Quick Guide to BoostingBoosting is an ensemble meta-algorithm that is primarily used for reducing bias and variance in supervised learning. It is a process that…5 min read·Mar 10, 2021----
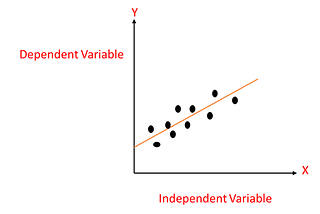
Swetha DhanasekarinGeek CultureSimple and Multiple Linear RegressionLinear regression is one of the well known and well understood algorithms in statistics and machine learning. It is one of the machine…4 min read·Mar 6, 2021----
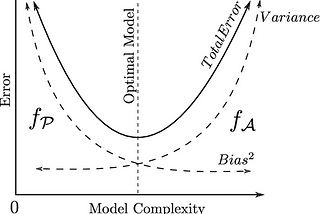
Swetha DhanasekarinNerd For TechBias and Variance Trade-offFor any model to perform well the error needs to be reduced. The correct balance of bias and variance is important for building any…4 min read·Mar 4, 2021----
Swetha DhanasekarRandom Forest Classifier- A Beginner’s GuideRandom Forest4 min read·Feb 21, 2021----
Swetha DhanasekarinGeek CultureA Simple Introduction to Decision Tree and Support Vector Machines (SVM)Decision tree and Support vector machines are the popular tools used in Machine learning to make predictions. Both these algorithms can be…5 min read·Feb 1, 2021----